Publications
-
[Journal Paper]P. Fafalios, Y. Marketakis, A. Axaridou, Y. Tzitzikas, M. Doerr, "A Workflow Model for Holistic Data Management and Semantic Interoperability in Quantitative Archival Research", Digital Scholarship in the Humanities (DSH), Oxford University Press, 2023. https://doi.org/10.1093/llc/fqad018
[pdf,bib] -
[Journal Paper]P. Fafalios, A. Kritsotaki, M. Doerr, "The SeaLiT Ontology - An Extension of CIDOC-CRM for the Modeling and Integration of Maritime History Information", ACM Journal on Computing and Cultural Heritage, 2023. https://doi.org/10.1145/3586080
[pdf,bib] -
[Conference Paper]G. Rinakakis, K. Petrakis, Y. Tzitzikas, P. Fafalios, "FastCat Catalogues: Interactive Entity-based Exploratory Analysis of Archival Documents", 2023 ACM/IEEE Joint Conference on Digital Libraries, Santa Fe (New Mexico, USA), 26-30 June 2023. https://doi.org/10.1109/JCDL57899.2023.00035
[pdf,bib] -
[Book Chapter]P. Fafalios, G. Samaritakis, K. Petrakis, K. Doerr, A. Kritsotaki, A. Axaridou, M. Doerr, "Building and Exploring a Semantic Network of Maritime History Data", In Mediterranean Seafarers in Transition (ISBN: 978-90-04-51419-5), Brill. 2022. https://doi.org/10.1163/9789004514195_019
[pdf,bib] -
[Preprint]A. Sklavos, P. Fafalios, Y. Tzitzikas, "Estimating the Cost of Executing Link Traversal based SPARQL Queries", arXiv preprint (arXiv:2210.09100), October 2022. https://doi.org/10.48550/arXiv.2210.09100
[pdf,bib] -
[Conference Abstract]P. Fafalios, "Historical Research meets Semantic Interoperability: The Documentation System SYNTHESIS and its Application in Art History Research", Abstract publised and presented (as a long presentation) at "Digital Humanities 2022", July 25-29, 2022. https://doi.org/10.5281/zenodo.7541211
[pdf,bib,slides] -
[Journal Paper]Y. Tzitzikas, M. Mountantonakis, P. Fafalios, Y. Marketakis, "CIDOC-CRM and Machine Learning: A Survey and Future Research", Heritage 2022, 5(3), 1612-1636, 2022. https://doi.org/10.3390/heritage5030084
[pdf,bib] -
[Conference Paper]P. Fafalios, K. Konsolaki, L. Charami, K. Petrakis, M. Paterakis, D. Angelakis, Y. Tzitzikas, C. Bekiari, M. Doerr, "Towards Semantic Interoperability in Historical Research: Documenting Research Data and Knowledge with Synthesis", Proceedings of the 20th International Semantic Web Conference, Springer, 24-28 October 2021. https://doi.org/10.1007/978-3-030-88361-4_40
[pdf,bib,slides] -
[Journal Paper]P. Fafalios, K. Petrakis, G. Samaritakis, K. Doerr, A. Kritsotaki, Y. Tzitzikas, M. Doerr, "FAST CAT: Collaborative Data Entry and Curation for Semantic Interoperability in Digital Humanities", ACM Journal on Computing and Cultural Heritage, 2021. https://doi.org/10.1145/3461460
[pdf,bib] -
[Journal Paper]K. Petrakis, G. Samaritakis, T. Kalesios, E. García Domingo, A. Delis, Y. Tzitzikas, M. Doerr, P. Fafalios, "Digitizing, Curating and Visualizing Archival Sources of Maritime History: the case of ship logbooks of the nineteenth and twentieth centuries", Drassana, No. 28, 60–87, 2020. https://doi.org/10.51829/Drassana.28.649
[pdf,bib]
Talks / Presentations
-
[Invited Talk]P. Fafalios, "Workflow Model and Tools for Holistic Data Management and Semantic Interoperability in Archival Research", Metaphacts, October 27, 2022. [slides] -
[Conference Talk]P. Fafalios, "Historical Research meets Semantic Interoperability: The Documentation System SYNTHESIS and its Application in Art History Research", Digital Humanities 2022, July 25-29, 2022. [slides] -
[Conference Talk]P. Fafalios, "Advanced IT Tools for Historical Research with Archival Material", 8th IMHA International Congress of Maritime History, Porto, Portugal, June 28 - July 02, 2022. [slides] -
[Conference Talk]P. Fafalios, "Digital Seafaring: Digitising, Curating and Exploring Archival Sources of Maritime History", Baltic Connections 2022, University of Jyväskylä, Finland, June 16–17, 2022. [slides] -
[Conference Talk]P. Fafalios, "Advanced IT Tools for Holistic Data Management in Historical Archival Research", Final Conference of the SeaLiT Project, Institute of Mediterranean Studies - FORTH, Rethymno, June 9–11, 2022. [slides] -
[Meeting Talk]A. Kritsotaki and P. Fafalios, "The SeaLiT Ontology - An extension of CIDOC-CRM for the modelling of Maritime History information", Joint meeting of the 52nd CIDOC CRM SIG and 45th FRBR SIG, Online Meeting, February 8-11, 2022. [slides] -
[Conference Talk]P. Fafalios, "Towards Semantic Interoperability in Historical Research: Documenting Research Data and Knowledge with Synthesis", International Semantic Web Conference, Online Conference, October 26, 2021. [slides, video] -
[Seminar Talk]P. Fafalios, "Semantic documentation of research data and knowledge in the field of Art History with the SYNTHESIS system", Web Seminar on Quantitative and Qualitative Data Analysis in Historical Research, FORTH-ICS, October 7, 2020. [slides, video in Greek] -
[Conference Talk]P. Fafalios, "Challenges and solutions towards creating a semantic network of historical maritime data", Data for History 2021, Online Conference, June 30, 2021. [slides, video] -
[Invited Talk]P. Fafalios, "Digital Seafaring - Digitising, Curating and Exploring Archival Sources of Maritime History", Max Planck Institute for the History of Science (MPIWG), June 8, 2021. [slides] -
[Seminar Talk]P. Fafalios, "Documentation of Scientific Research in the Humanities and Social Sciences - The European projects SeaLiT, RICONTRANS and ReKnow", Web Seminar on Information Systems for the Documentation of Scientific Research in the Humanities and Social Sciences, FORTH-ICS, September 24, 2020. [slides, video in Greek]
Workflows, Data Models & Datasets
-
Workflow Model for Archival Research | A data workflow model for holistic data management and semantic interoperability in quantitative archival research
Archival research is a complicated task that involves several diverse activities for the extraction of evidence and knowledge from a set of archival documents. The involved activities are usually unconnected, in terms of data connection and flow, making difficult their recursive revision and execution, as well as the inspection of provenance information at data element level.
We have introduced a workflow model (depticted below) for holistic data management in quantitative archival (historical) research; from transcribing and documenting a set of archival documents, to curating the transcribed data, integrating it to a rich semantic network (knowledge graph), and then exploring the integrated data quantitatively. The workflow is provenance-aware, highly-recursive and focuses on semantic interoperability, aiming at the production of sustainable data of high value and long-term validity.
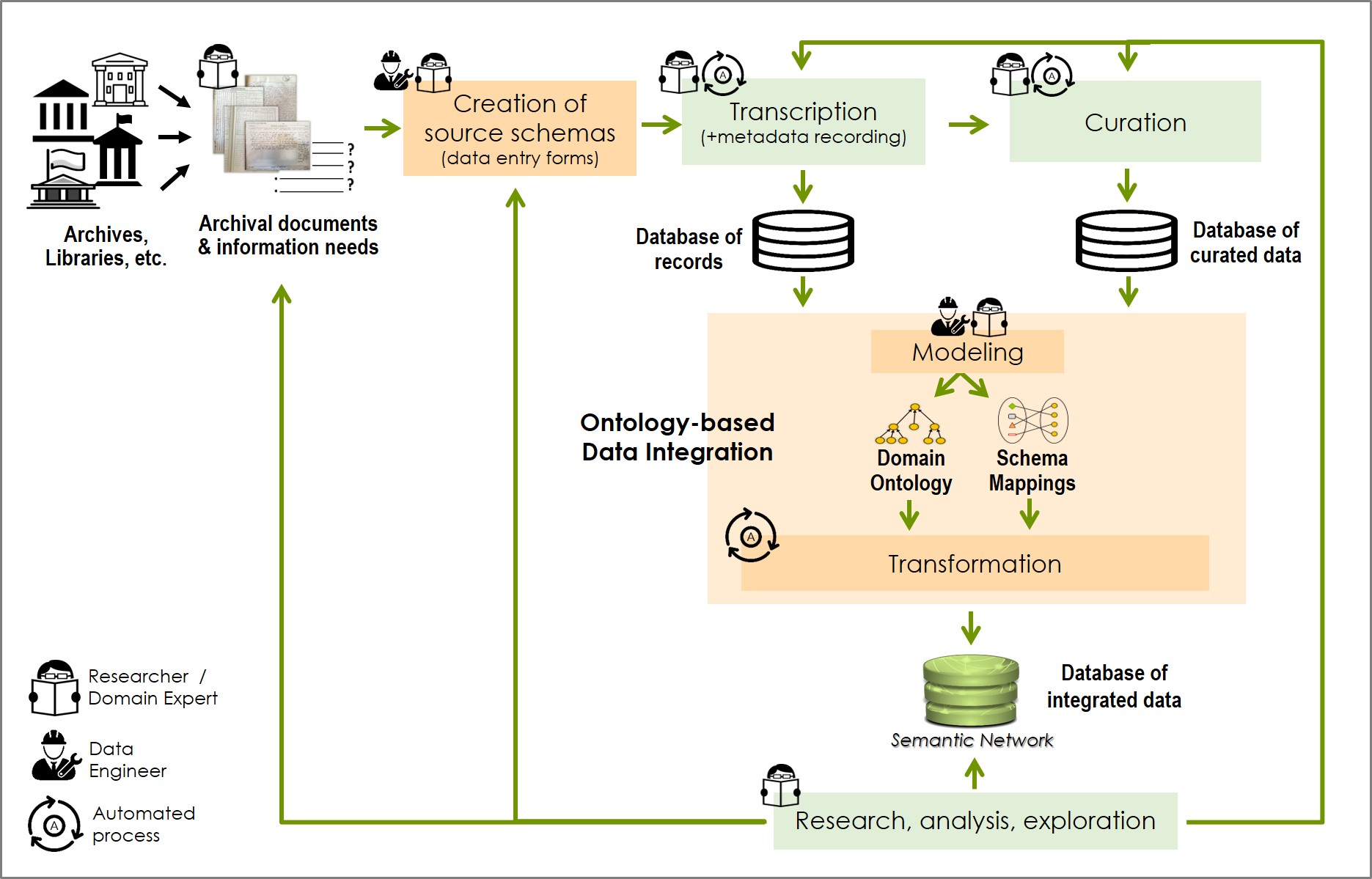
More information about the workflow model, and its application in a real use case in the domain of maritime history research, is available in our DSH article.
- SeaLiT Ontology | An extension of CIDOC-CRM for the modelling and integration of maritime history information
The SeaLiT Ontology is a formal ontology intended to facilitate the integration, mediation and interchange of heterogeneous information related to maritime history. It aims at providing the semantic definitions needed to transform disparate, localised information sources of maritime history into a coherent global resource. It also serves as a common language for domain experts and IT developers to formulate requirements and to agree on system functionalities with respect to the correct handling of historical information.
The figure below shows how information about a ship voyage is modelled in the ontology:
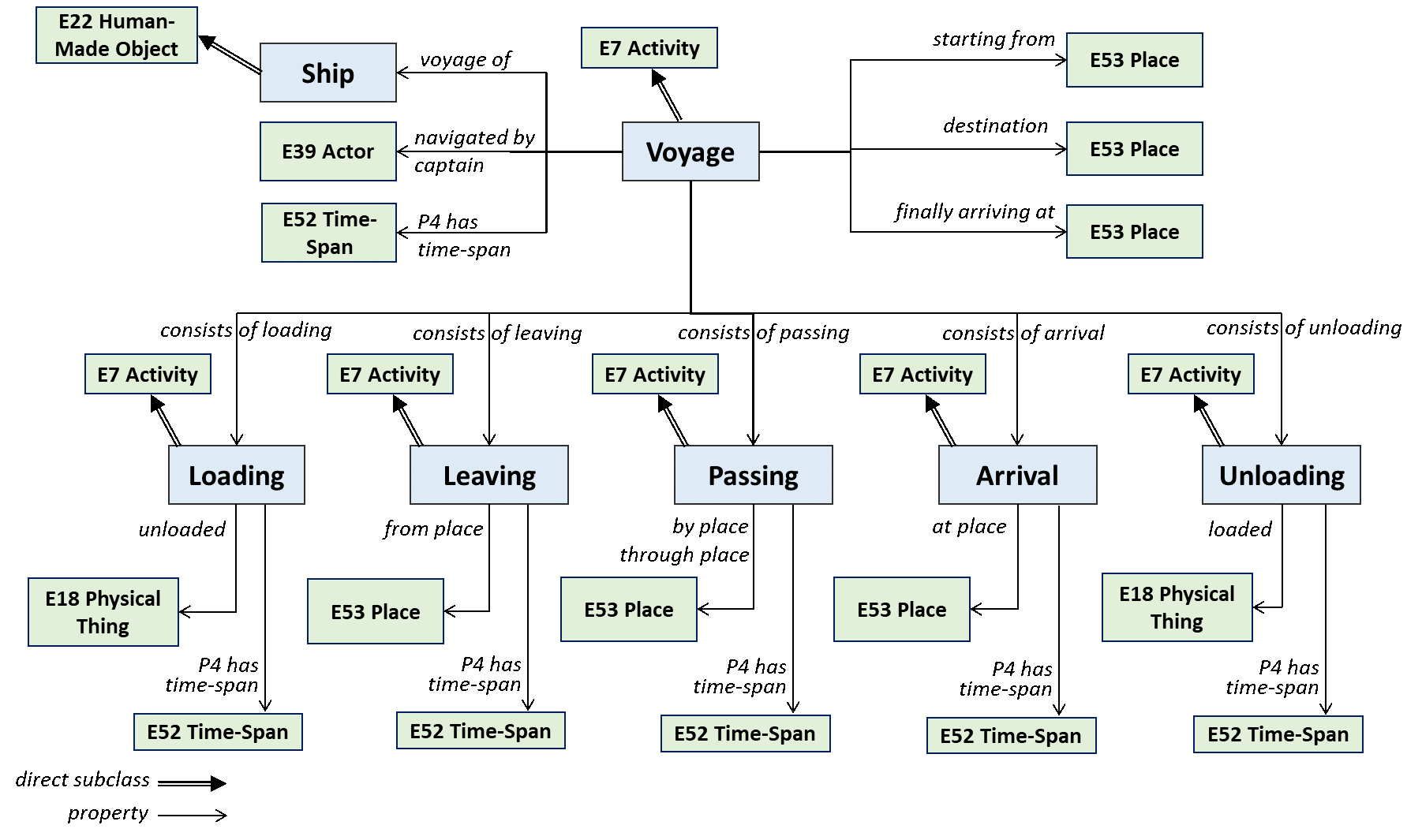
The definition of the SeaLiT Ontology, together with its RDFS implementation, are available through Zenodo (under a creative commons license): https://doi.org/10.5281/zenodo.6797750 (DOI: 10.5281/zenodo.6797750).
The (resolvable) namespace of the ontology is: http://www.sealitproject.eu/ontology/
For more information about the SeaLiT ontology, its construction, and use in the SeaLiT project, check our JOCCH article.
- SeaLiT Knowledge Graphs | Integrated maritime history data in RDF
SeaLiT Knowledge Graphs is an RDF dataset of maritime history data that has been transcribed (and then transformed) from original archival sources in the context of the SeaLiT Project (Seafaring Lives in Transition, Mediterranean Maritime Labour and Shipping, 1850s-1920s). The underlying data model is the SeaLiT Ontology, an extension of the ISO standard CIDOC-CRM (ISO 21127:2014) for the modelling and integration of maritime history information.
The knowledge graphs integrate data of totally 16 different types of archival sources, including crew and displacement lists, registers of different types (sailors, naval ships, students, etc.), payrolls, censuses, and employment records. Data from these archival sources has been transcribed in tabular form and then curated by historians of SeaLiT using the FastCat system. Data exploration applications over these sources are publicly available (SeaLiT Catalogues, SeaLiT ResearchSpace).
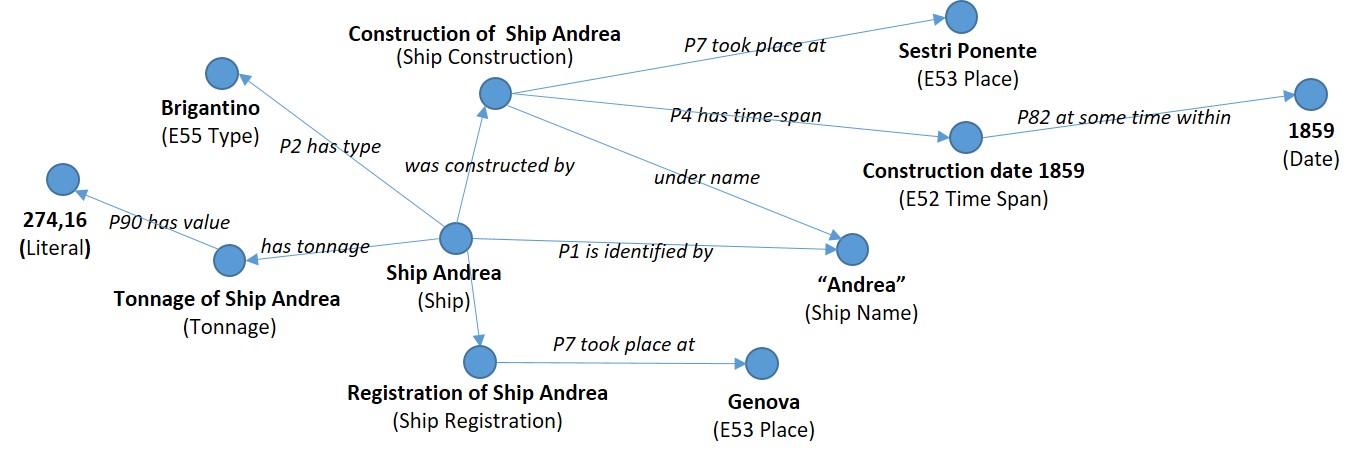
The dataset is available through Zenodo (under a creative commons license): https://doi.org/10.5281/zenodo.6460841
- CRMinf | An extension of CIDOC-CRM to support argumentation and inference making
CRMinf is a formal ontology compatible with CIDOC-CRM, intended to be used as a global schema for integrating metadata about argumentation and inference making. Its primary purpose is to enable the description of the semantic relationships between the premises, conclusions and activities of reasoning.
We have worked on a full revision of the "Belief Adoption" notion of CRMinf by introducing new classes and properties and revising the scope of existing ones. Working with data of the RICONTRANS projects was one of the motivating factors for revising and expanding the model. A depiction of the new model is shown below:
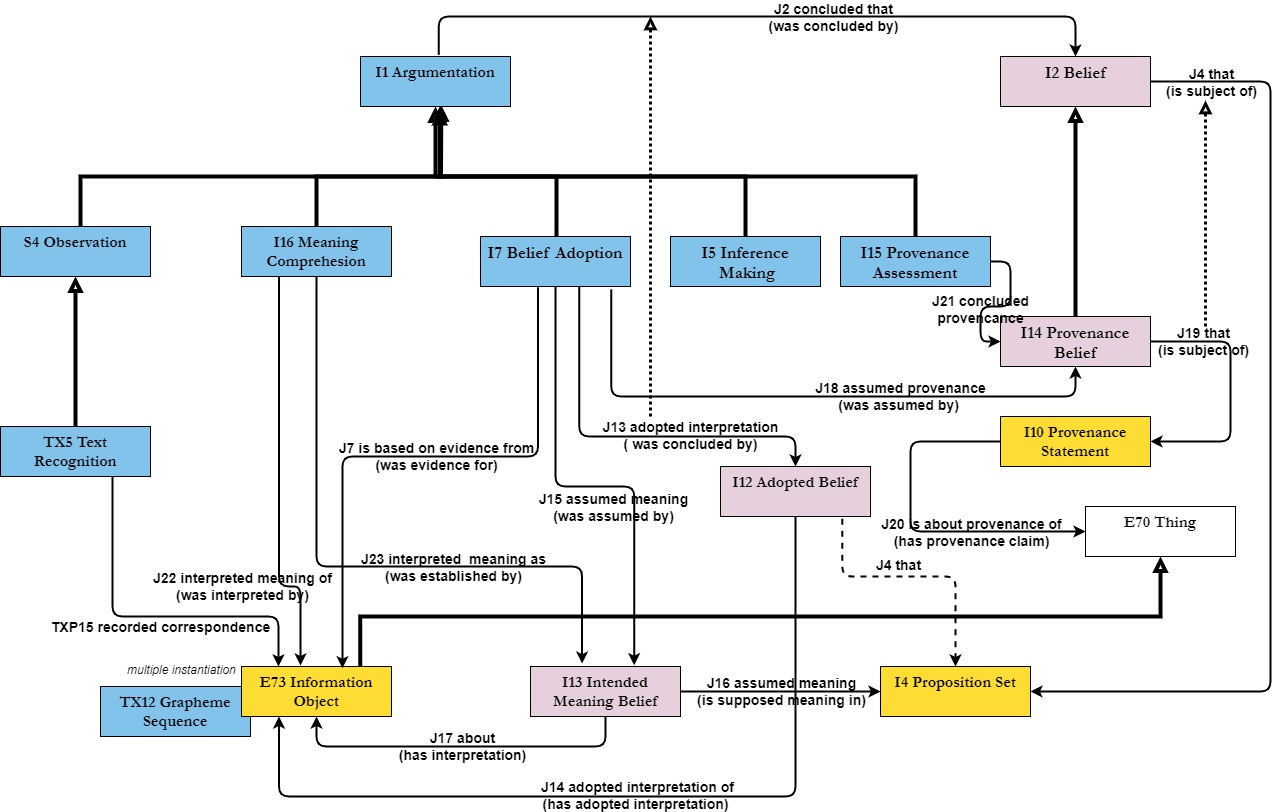
The plan is to prepare a new version of the definition document of CRMinf based on this new modeling and propose it to CIDOC CRM SIG for approval.
- CRMtex | An extension of CIDOC CRM to model ancient textual entities
CRMtex is a formal ontology intended to support the study of ancient/historical texts by identifying relevant textual entities and by modelling the scientific process related with their investigation in order to foster integration with other cultural heritage research fields.
We have collaborated with the current editors/maintainers of CRMtex, Achille Felicetti and Francesca Murano, for improving the model by revising the notion of "Text Recognition" and introducing new classes and properties. Working with data of the RICONTRANS projects was one of the motivating factors for revising and expanding the model.
A depiction of the new version of the model (showing also its connection with CRMinf) is shown below:
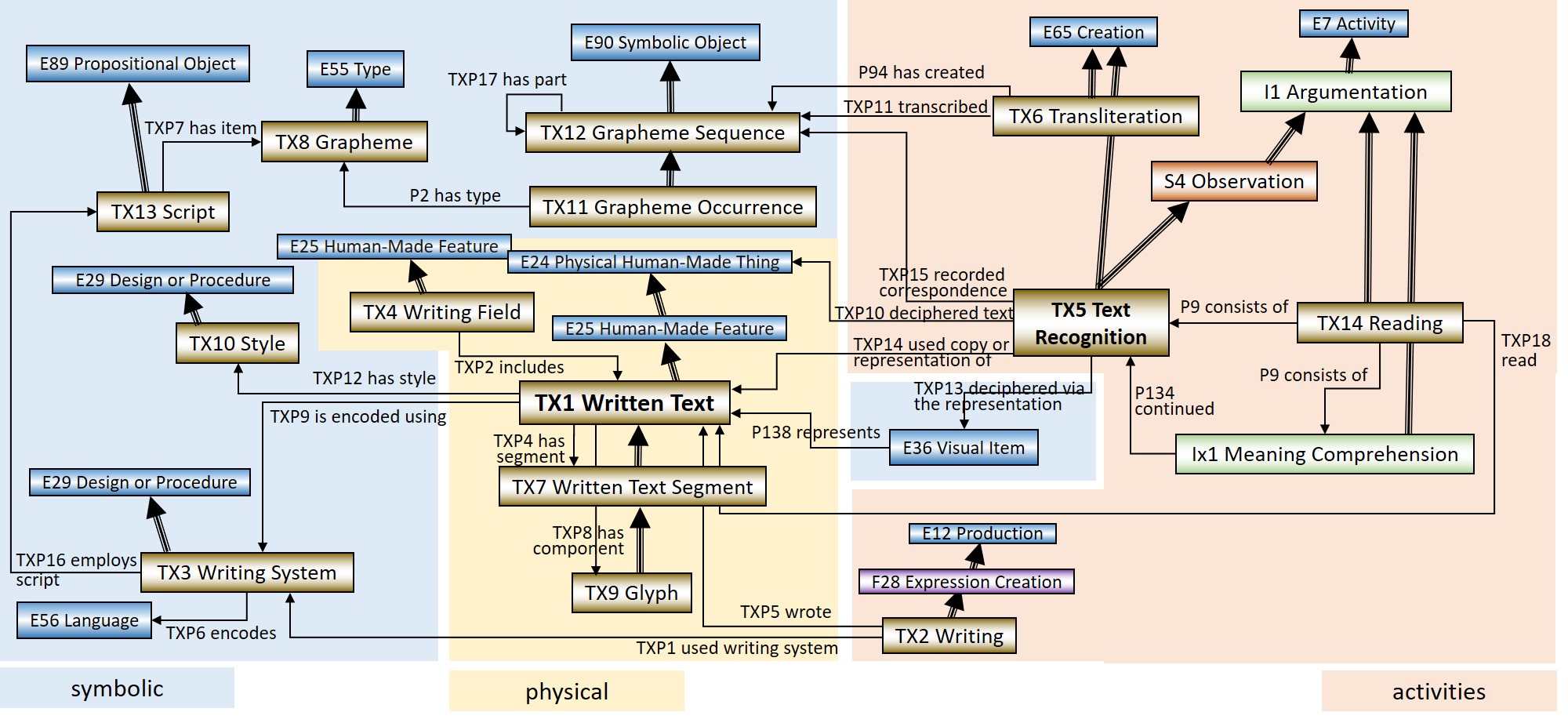
The plan is to prepare a new version of the definition document of CRMtex based on this new modeling and propose it to CIDOC CRM SIG for approval.
Software
- FastCat | Collaborative transcription and curation of archival data
FastCat is a Web-based system designed for historians and other researchers who need to digitize and curate structured or semi-structured archival documents in a fast and accurate way in order to create their research dataset. It combines the ease of use and quick data entry functions of the classic spreadsheet with the information accuracy typically associated with a complex database. It does so by offering data entry templates designed to mirror, in the digital space, the structure and data entry logic of the original source.
In FastCat, archival documents are transcribed as ‘records’ belonging to specific ‘templates’, where a ‘template’ represents the structure of a single type of archival source. A record organizes the data and metadata in tables, offering functionalities like nesting tables and selection of term from a vocabulary. The system requires login and runs locally inside any modern web browser with possibility of automated synchronisation with an online database.
The transcribed data can be curated using FastCat Team, a special environment within FastCat that allows the collaborative curation of the 'entities' and 'vocabulary terms' that appear in the transcripts.
FastCat has been widely used in the context of the SeaLiT project, for supporting a large group of historians in transcribing and curating a large and diverse set of archival sources related to maritime history. Historians have already transcribed more than 600 records belonging to 20 different types of archival sources.
FastCat is available as open source through GitHub: https://github.com/isl/FastCat
For more information about FastCat and its use in the SeaLiT project, check our JOCCH article.
- FastCat Catalogues | Exploring transcripts of archival documents
FastCat Catalogues is a Web application that supports researchers studying archival material, such as historians, in exploring and quantitatively analysing the data (transcripts) of their archival sources. The application makes use of JSON technology and is configurable for use over any type of archival documents whose contents have been transcribed and exported in JSON format.
The supported functionalities include:
- source- or record-specific entity browsing
- entity browsing across sources
- data filtering and ranking
- inspection of the provenance of any piece of information (important for verification or further data exploration)
- data aggregation and visualisation in charts
- data export for further (external) analysis
FastCat Catalogues was developed by Giorgos Rinanakis, an undergraduate student of the Computer Science Department of University of Crete, as part of his bachelor thesis, under the supervision of Pavlos Fafalios.
The application has been deployed in the context of the SeaLiT project for supporting historians in exploring a large and diverse set of archival sources related to maritime history. The deployment is available for use at: https://catalogues.sealitproject.eu/
The system is available as open source through GitHub: https://github.com/isl/FastCat-Catalogues
-
SeaLiT ResearchSpace | Exploring Integrated Archival Data of Maritime History
SeaLiT ResearchSpace is a web application that supports historians in exploring and quantitatively analyzing archival data of maritime history, transcribed and integrated (using SeaLiT Ontology) from a large and diverse set of archival sources. The context of this work is the project SeaLiT, a large research project in the field of maritime history which studies the transition from sail to steam navigation and its effects on seafaring populations in the Mediterranean and the Black Sea (1850s - 1920s).
The application makes use of ResearchSpace, an open-source data management platform which offers several access methods over semantic data, including keyword search and a powerful assistive query building interface, as well as a variety of results visualization methods including tables and charts. The interfaces offered by ResearchSpace have been configured considering the needs of the SeaLiT project and the characteristics of the underlying data.
The application is available as open source through GitHub (https://github.com/isl/SeaLiT-ResearchSpace), while a deployment is publicly available for use at: http://rs.sealitproject.eu/.
For more information about the functionalities offered by SeaLiT ResearchSpace as well as the overal process of building a rich semantic network of integrated archival data, check our Brill book chapter.
- Synthesis RICONTRANS | Documenting data in Art History research
Synthesis RICONTRANS is a web-based application for the collaborative and controlled documentation of data and knowledge in Art History research. It is multilingual, configurable, and utilizes XML technology, offering flexibility in terms of versioning, workflow management and data model extension. It's focus is on semantic interoperability, and achieves this by making use of standards for data modelling, in particular the formal ontology CIDOC-CRM (ISO 21127:2014). The aim is the production of data with high value and long-term validity that can be (re)used beyond a particular research activity.
The system offers a wide range of functionalities including:
- documenting rich data and metadata about the following types of entities: Objects, Object Transfers, Routes, Archival Sources, Books, Newspapers and Periodicals/Reviews, Oral History Sources, Web Sources, Bibliography, Source Passages, Collection of Source Passages, Researcher Comments, Historical Figures, Historical Events, Collections, Locations, Persons, Organizations, Digital Objects
- interlinking of the documented entities (forming a network of interrelated entities)
- management of static and dynamic vocabularies
- linking to thesauri of terms
- connection with geolocation services (TGN, Geonames)
- map visualization for certain types of entities
- support of comparable historical time expressions (e.g., ca. 1920, early 16th century)
- management of digital files (images, etc.)
- transformation of the documented information to an RDF knowledge base (Linked Data)
The system has been widely used in the context of the RICONTRANS project, whose research focus is the Russian religious artefacts brought from Russia to the Balkans after the 16th century and which are now preserved in churches, monasteries or museums. More than 8,000 entities have been already documented, including around 2,000 objects, 740 object transers, 230 archival sources, 1,000 source passages, and 260 historical figures.
Synthesis RICONTRANS is based on and extends Synthesis-Core, an information system for the scientific and administrative documentation of cultural entities which makes use of FIMS, an open-source system suitable for documenting, recording and managing XML files stored in an XML database.
The configuration used in Synthesis RICONTRANS is publicly available through GitHub: https://github.com/isl/SynthesisRICONTRANS-Schemas. The repository provides the documentation schema (in XSD format) of each different type of supported entity. The final structure of each schema is the result of lengthy discussions between domain experts (art historians) and data engineers, and has revised several times due to new insights acquired in the course of research.
For more information about Synthesis and its use in the RICONTRANS project, check our ISWC paper.
-
A-QuB-2 | A Web Application for Querying and Exploring Semantic Data
A-QuB-2 is a web application that facilitates the exploration of semantic (RDF) data by plain users. It offers an intuitive, user-friendly interface that supports users in building and running complex queries step-by-step, without needing to know and write SPARQL. Its powerful configuration model allows setting up the application for use over any knowledge base, independent of the underlying data model / ontology.
The supported functionalities include:
- Assistive query building interface that exploits the connections of the KB entities
- Data filtering based on entity, text, number range, date range, boolean value, map area
- Results visualisation in table
- Results browsing by exploiting the entity interconnections
- Results download in CSV format for further (offline) analysis
- Configuration for use over any KB through a properties file
The system is an extension of a previous version (called A-QuB), developed by the Information Systems Laboratory of FORTH-ICS, in the context of the H2020 project VRE4EIC (No 676247), and described in a demo paper. Our new version a) implements a configuration model that allows fully configuring the application through a properties file, b) has been extended for supporting additional functionalities, such as filtering by number range, boolean value, date range (including expressions like '20th century', 'decade of 1970', etc.), and others.
The system is available as open source through GitHub: https://github.com/isl/A-QuB-2
- LDAQ-CostEstimators | Estimating the Cost of Executing Link Traversal based SPARQL Queries
Semantic technologies are increasingly used in a plethora of topical domains, including the empirical and descriptive sciences, for making data available openly and interoperable for research and wide use. Following the Linked Data principles and the SPARQL language and protocol, such online RDF datasets can be directly accessed and queried by interested parties and external applications.
Nevertheless, the low reliability of SPARQL endpoints is the major bottleneck that deters the wider exploitation of such knowledge bases by third parties and real applications. Link traversal is an alternative SPARQL query processing method which relies on the Linked Data principles to answer a query by accessing (resolving) online web resources (URIs) dynamically, during query execution, without accessing endpoints. This query processing method is based on robust web protocols (HTTP, IRI), is in line with the dynamic nature of the Web, motivates decentralisation, and enables answering queries without requiring data providers to setup and maintain costly servers/endpoints.
However, the execution time of link traversal queries can become prohibitively high for certain types of queries due to the very high number of resources that need to be resolved at query execution time for retrieving their RDF triples. This performance issue is a reason that deters the wider adoption of this query evaluation method.
To this end, we have developed a set of baseline methods to estimate the execution cost of queries that can be answered through link traversal. Our focus is, in particular, on zero-knowledge link traversal, which does not consider a starting graph or seed URIs for initiating the traversal, relying only on URIs that exist in the query pattern or that are dynamically retrieved during query execution. The first method considers very limited knowledge about the underlying knowledge base, the second considers predicate statistics (average number of subject/object bindings, computed once in a pre-processing step), the third method extends the second by also considering star-shaped joins, while the last method extends all previous methods by also considering FILTER clauses.
By using these methods, a query service can estimate the link traversal cost and thus decide on the fly the query execution strategy to follow for an incoming SPARQL query, based on factors such as the expected query execution time of link traversal and the availability or load of the endpoint.
To enable the comparative evaluation of cost estimation methods, we have also created a ground truth dataset consisting of 2,425 queries.
The implemenation was done by Antonios Sklavos, an undergraduate student of the Computer Science Department of University of Crete, as part of his bachelor thesis, under the supervision of Pavlos Fafalios.
The library containing the implementation of the four methods and the ground truth dataset is available as open source through GitHub: https://github.com/isl/LDAQ-CostEstimators
For more information about the methods, their evaluation and the ground truth, check our preprint paper.